Transparent and out-of-box sharding support for ETS tables in Erlang/Elixir.
This blog post is about how to scale-out ETS tables and be able to support high levels of concurrency without worrying about write-locks. Here is where Shards comes in. Shards is an Erlang/Elixir tool compatible with the ETS API, that implements Sharding support on top of ETS totally transparent and out-of-box.
Introduction
I’ll start saying that ETS tables are just great, they work incredible well and it’s pretty hard to beat them. To start suffering by locks issues (specially write-locks), it might require a huge traffic, probably millions of processes executing operations against a single ETS table, again, specially write operations – which involves locks. But for most of the cases, ETS is more than enough.
But, there might be scenarios where a single ETS table is not enough, probably scenarios with high levels of concurrency where write-locks becomes to a real problem, and you need a good way to scale-out your ETS tables. One of the most common architectural patterns to deal with this problem is Sharding/Partitioning. For that reason, in many cases we’re forced to implement Sharding on top of ETS tables ourselves, in order to balance load across multiple ETS tables instead of a single one, avoiding contention and being able to scale linearly – on-demand.
Because of that, it would be great to have a library/tool with the same ETS API, implementing Sharding/Partitioning on top of ETS totally transparent, with a very good performance/throughput and with the ability to scale linearly – go increasing number of shards as long as traffic increases to avoid suffering by locks and performance issues. Well, now it exist, let me introduce Shards, which is exactly the library/tool what we were talking about.
Shards
Shards implements a layer on top of ETS, compatible with ETS API and adding Sharding support transparently.
When a table is created using shards, that logical table is mapped to N physical ETS tables, being N the number of shards – passed as argument when the table is created. Once the table shards are created, key-based operations like: insert/2, lookup/2, delete/2, etc., are distributed uniformly across all shards. Operations like select, match, delete_all_objects/2, etc., are implemented following a map/reduce pattern, since they have to run on all shards. But remember, you only have to worry about to use the API (which it’s the same ETS API), the magic is performed by shards behind the scenes.
Now let’s see what happens behind scenes when we create/delete a table using shards.
% let's create a table, such as you would create it with ETS, with 4 shards
shards:new(mytab1, [{n_shards, 4}]).Exactly as ETS, shards:new/2 function receives 2 arguments, the name of the table and
the options – shards adds some extra options, please check out the repo to know more about it HERE.
Let’s create another table:
% create another one with default number of shards, which is the total of online
% schedulers – in my case is 8 (4 cores, 2 threads each).
% This value is calculated calling: erlang:system_info(schedulers_online)
shards:new(mytab2, []).
% now open the observer so you can see what happened
observer:start().If you open the observer app, you’ll see something like this:
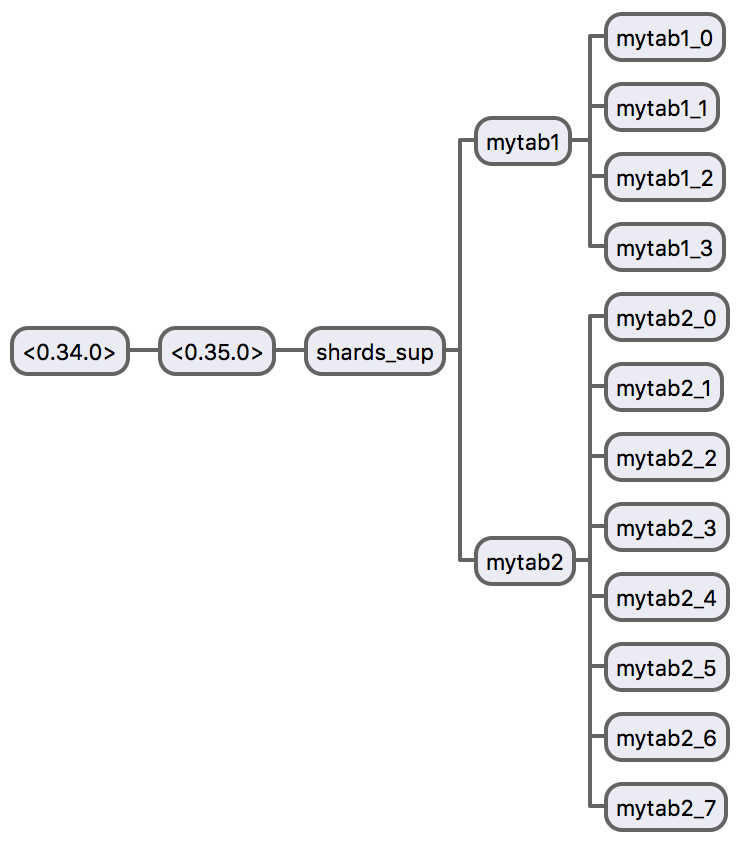
This is the process tree of shards application. When you create a new “table”, a new supervision tree is created.
- Each logical table has its own supervision tree – dedicated only to that group of shards.
- Each supervision tree has a main supervisor named with the same name of the table.
- Each supervisor has a pool of workers (
gen_server) – the pool size is the number of created shards. - Each worker or shard’s owner, is responsible to create the assigned shard represented by an ETS table.
- When you delete the table (
shards:delete/1), the supervision tree is deleted, therefore, all created shards (ETS tables) are deleted automatically.
Let’s delete a table:
shards:delete(mytab1).
observer:start().See how shards gets shrinks:
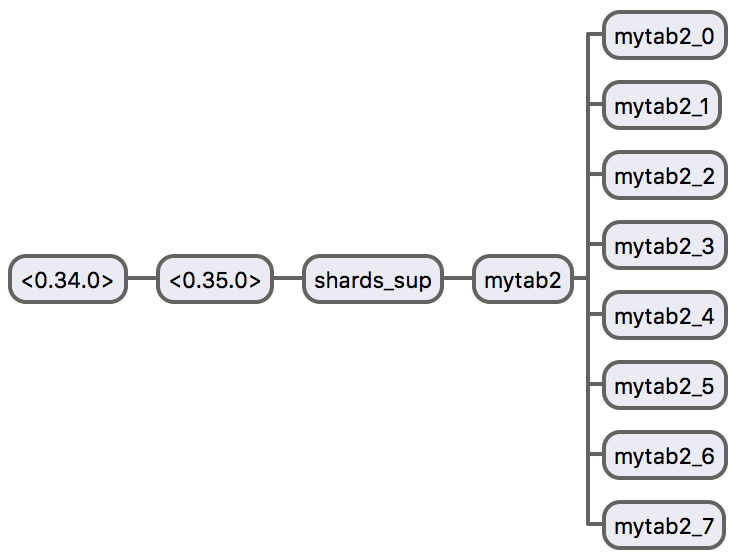
Shards behaves elastically, more shards can be added/removed dynamically.
Working with Shards
Now let’s execute some read/write operations:
% inserting some objects
> shards:insert(mytab1, [{k1, 1}, {k2, 2}, {k3, 3}]).
true
% let's check those objects
> shards:lookup(mytab1, k1).
[{k1,1}]
> shards:lookup(mytab1, k2).
[{k2,2}]
> shards:lookup(mytab1, k3).
[{k3,3}]
> shards:lookup(mytab1, k4).
[]
% delete an object and then check
> shards:delete(mytab1, k3).
true
> shards:lookup(mytab1, k3).
[]
% now let's find all stored objects using select
> shards:select(mytab1, ets:fun2ms(fun({K, V}) -> {K, V} end)).
[{k1,1},{k2,2}]As you may have noticed, it’s extremely easy, it’s like use ETS, but using shards module instead. Remember, almost all ETS functions are implemented by shards as well.
More about Shards
Shards is composed by 4 main modules:
- shards_local: Implements Sharding on top of ETS tables, but locally (on a single Erlang node).
-
shards_dist: Implements Sharding but across multiple distributed Erlang nodes, which must run
shardslocally, sinceshards_distusesshards_localinternally. -
shards: This is a wrapper on top of
shards_localandshards_dist. -
shards_state: This module encapsulates the
shardsstate.
To learn more about Shards please check it out on GitHub – you’ll find more documentation and examples about all its features.
Performance Tests
There is no better way to prove that it really works and worth than with performance tests. Therefore, this section presents a set of tests that were made in order to show how shards behaves compared with ets – especially under heavy load.
Performance tests are not easy to perform, so one of the best recommendation is to find a good tool to help with that. In this case, tests were done using basho_bench tool. I strongly recommend it, it’s a very good tool, simple, easy to use, provides graphics, examples, etc. Read more about it: Basho Bench.
NOTE: The original repository of basho_bench was forked in order to add
shardsdriver. You can find it HERE.
Test Environment
- Laptop MacBook Pro (OSX El Capitan)
- Hardware: 4 cores, 16G of RAM, 256G SSD
- Erlang OTP 18.2.1
Latencies
In the next figure, we can notice how is the latency trend for each module. Latencies for ets tends to increase with the traffic faster than shards, which is precisely the goal, be able to scale across locks, adding more shards as long as traffic increases. In this case, the test was done using 4 shards, and you can see how with the generated traffic (~150.000 ops/sec), shards and shards_local latencies were better than ets – only a few microseconds but the thing is there was an improvement.
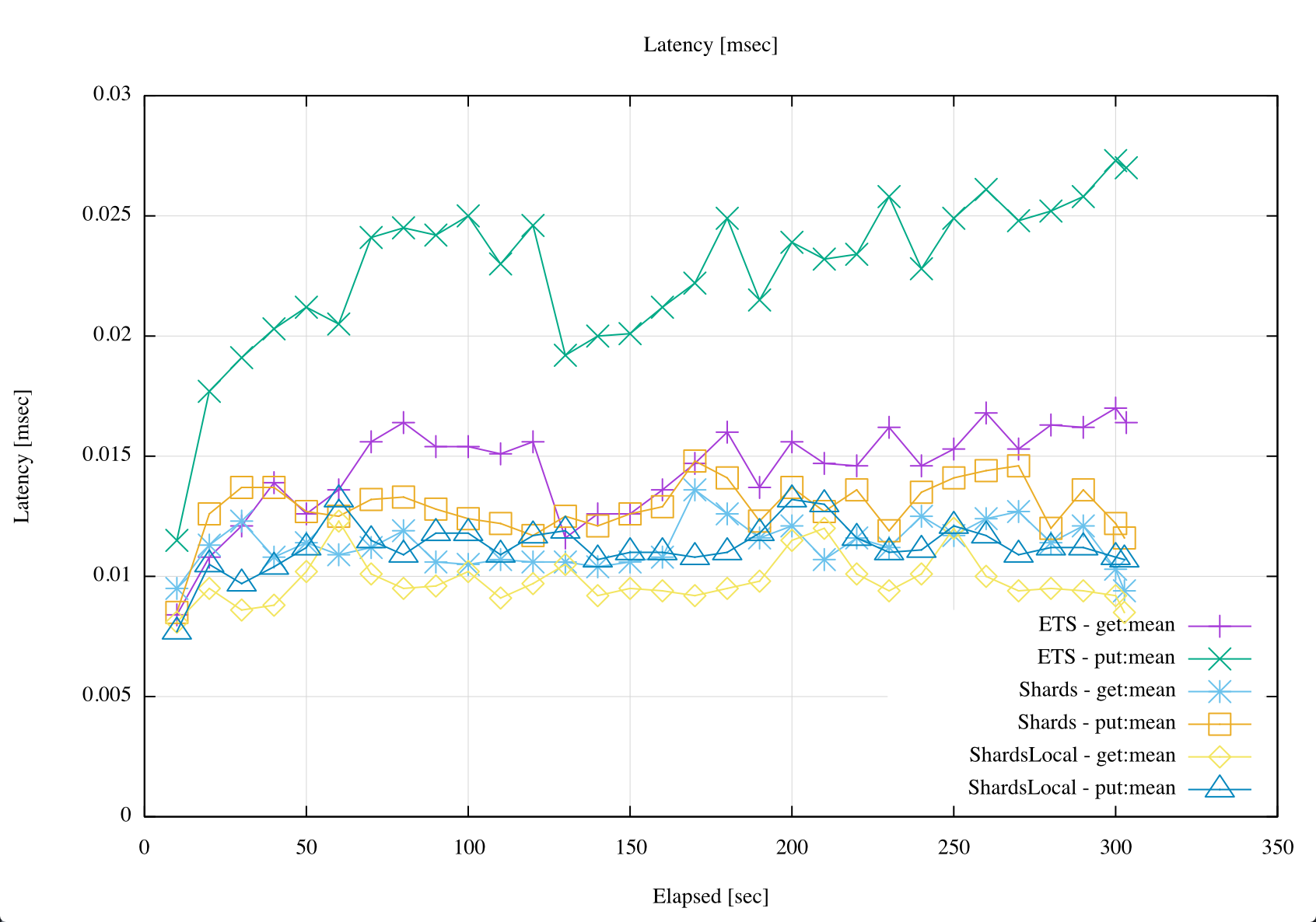
Latencies: ets vs shards vs shards_local.
Throughput
The max generated throughput was ~150.000 ops/seg for all compared modules – oscillations were between 100.000 and 200.000 ops/sec.
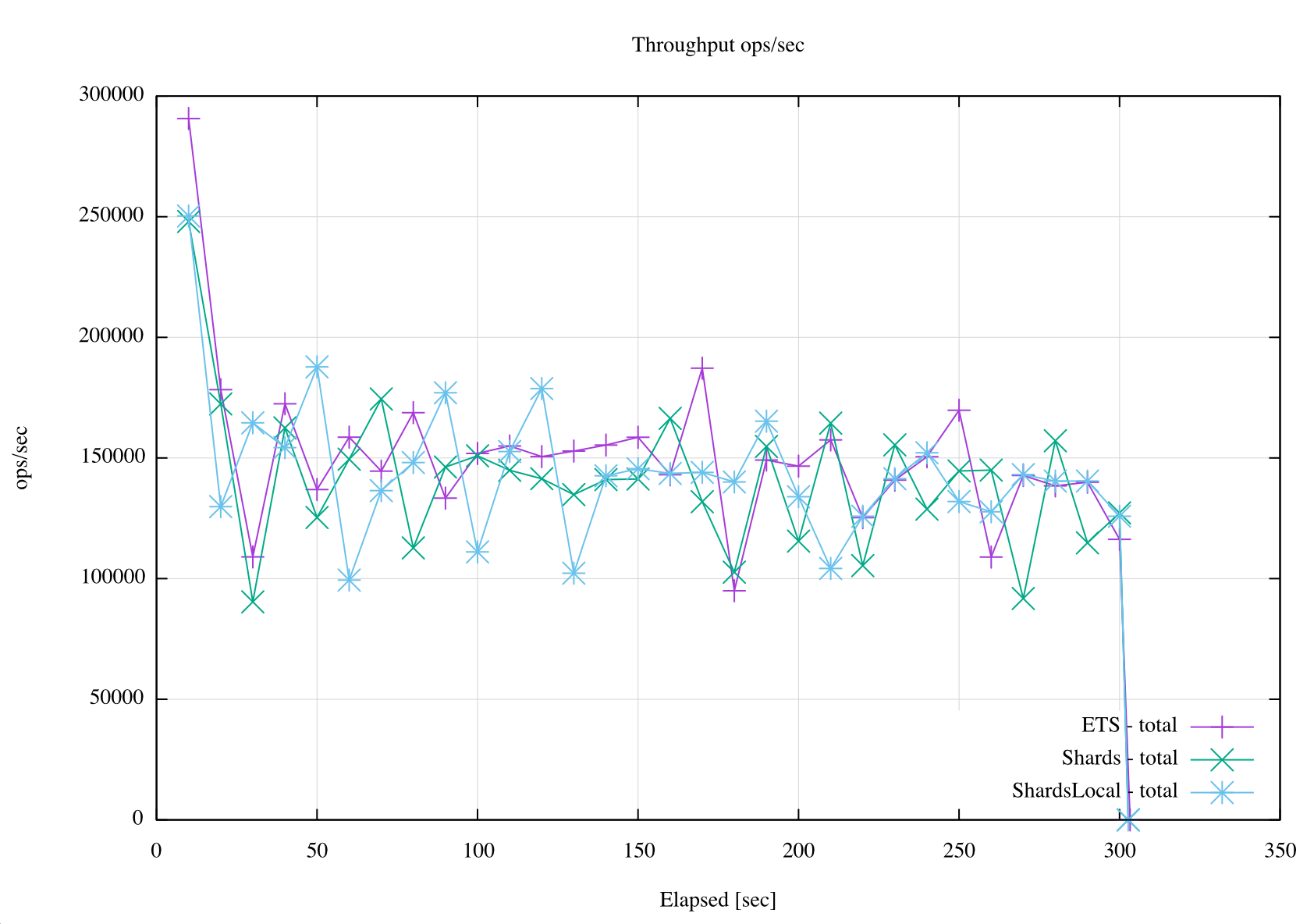
Throughput: ets vs shards vs shards_local.
Unfortunately, due to Hardware limitations, it wasn’t possible to do the tests at least with one million of ops/seg. However, any help is welcome and would be great!
Summing Up
It’s clear that Sharding is the way to go when we start suffer of locks and/or contention. And shards is the library/tool to help with that, in order to avoid implement Sharding over and over again on top of ETS tables ourselves.
For more information please visit the Shards GitHub Repo.